
Modern financial institutes rely heavily on data from many resources for their various activities, from pricing and trading to risk management. In this blog post we will discuss how Databricks as a data platform could help institutes operate seamlessly and overcome the possible drawbacks while maintaining the required transparency, control, and auditability.
What Databricks Is and Why It Matters for Financial Services
Databricks is a cloud-native unified data and analytics platform designed to run on public cloud infrastructure. It originated from the development of Apache Spark, an open-source distributed processing engine created to improve the performance and scalability limitations of traditional big-data systems. Spark introduced a new way of processing large volumes of data in memory, enabling faster batch analytics, real-time streaming, and advanced analytics within a single computational framework.
Databricks, founded by the original creators of Spark, makes these capabilities usable at enterprise scale by providing a managed, secure, and production-ready platform operating on cloud storage objects (like Amazon S3, Azure Data Lake Storage, Google Cloud Storage, etc.) with the separation of storage and compute. It can also integrate with on-premises and legacy systems like Oracle or Microsoft SQL Server for data ingestion. In such a case, it will not be a federated query engine; rather data will be consolidated into the lakehouse to support scalable analytics and workloads. Besides, the computation workloads are executed on elastic clusters managed by Databricks itself. This enables the organization to dynamically scale workloads without managing the underlying structures themselves, in comparison to the traditional Hadoop deployment.
Another advantage of Databricks over traditional data platforms is its architectural focus on unifying workloads that have historically been separated across multiple systems. Earlier enterprise architecture typically relied on distinct platforms for data ingestion (e.g. Informatica), data warehousing (e.g. Oracle Exadata), business intelligence (e.g. Tableau), and separate environments for advanced analytics and machine learning. Unless strict architectural guidelines are enforced, this separation quickly leads to duplicated data pipelines, lagging data silos, inconsistent governance, and increasing operational complexity. Databricks addresses this by enabling analytics, data engineering, and AI workloads to operate on a shared data foundation, reducing fragmentation while maintaining enterprise-grade control through centralized governance, fine grained access management, and end-to-end auditability.
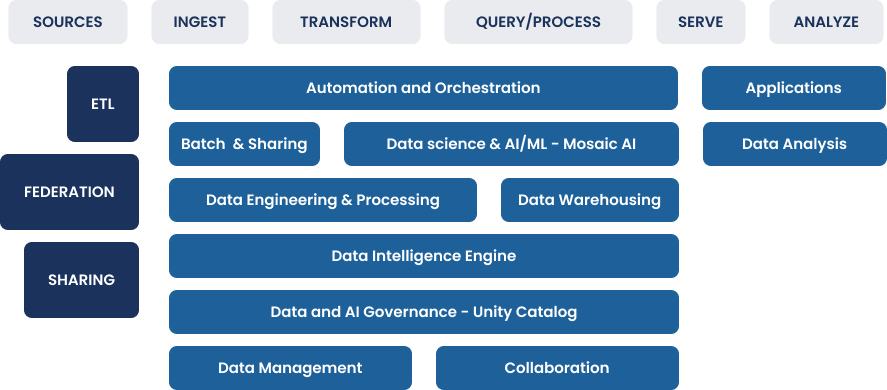
The Lakehouse Concept: One Platform for Data, Analytics, and AI
Enterprise data architectures in financial services have typically evolved in layers, combining data lakes for large-scale storage with data warehouses for regulatory reporting and standardized analytics, while adding separate platforms for advanced analytics and AI. While functional, this fragmentation creates challenges around governance, performance, and operational risk. Data lakes are flexible but difficult to control and optimize for business intelligence. On the other hand, data warehouses are reliable for reporting but limited when it comes to machine learning and unstructured data. As data is moved across platforms, latency, cost, and compliance risk increase.
During late 2010s the lakehouse architecture emerged in response to these challenges and has been discussed in both academia and industry contexts as an evolution of large-scale data architecture. Its core idea is to combine the low cost and scalable storage of data lakes with the performance and reliability of the data warehouses. It is built on concepts such as schema-on-read, distributed processing, and transactional metadata. Rather than separating systems by workload type, it enables different teams and use cases to operate on the same governed data. It operates on a shared data layer, augmented with metadata, schema enforcement, and transaction management. Practically it goes beyond simply dumping files in a blob storage. It relies on open table formats, centralized metadata, and transactional guarantees to ensure that structured data can be queried reliably via SQL, while less structured data remains accessible for data engineering and AI use cases.
Open technologies play a central role in this approach. By relying on open data formats, such as columnar formats like Apache Parquet and open table formats like Apache Iceberg or Delta Lake) and cloud-based storage, organizations retain control over their data and avoid dependency on proprietary storage layers and vendor lock-in. This flexibility is particularly important for enterprises operating across multiple cloud providers or regions.
End-to-End Data Management with Databricks
Databricks implements the lakehouse concept through an integrated platform designed to support the full data lifecycle.
A. Data Ingestion and EngineeringOrganizations typically ingest data from a wide range of sources, including SaaS applications, transactional databases, files, logs, and streaming systems. Databricks supports both batch and real-time ingestion patterns, enabling incremental and reliable data pipelines.
By standardizing ingestion workflows (focused on extracting and loading data from different sources) and engineering workflows (focused on transformation, enrichment, quality checks, and curation into analytics-ready data products) teams can reduce manual effort and operational complexity. Traditionally in large organizations these workflows were often implemented using different technologies and owned by separate teams, making lineage maintenance and end-to-end governance very difficult. Databricks brings these workflows together on a single platform with shared execution models, metadata, and governance, which is particularly valuable where multiple teams contribute to and consume shared data assets.
B. Data Transformation and QualityOnce data is ingested, it must be transformed into reliable, reusable “data products”. A data product is any dataset or data artifact that has been processed, curated, and structured to serve a specific business or analytical purpose, making it easy for teams or applications to consume the previous stage’s “product”. Databricks tools such as Delta Lake tables, Feature Store assets, and declarative pipelines enable teams to build, manage, and maintain these reusable products. Databricks supports declarative data pipelines that allow teams to define transformations, dependencies, and quality expectations in a structured way.
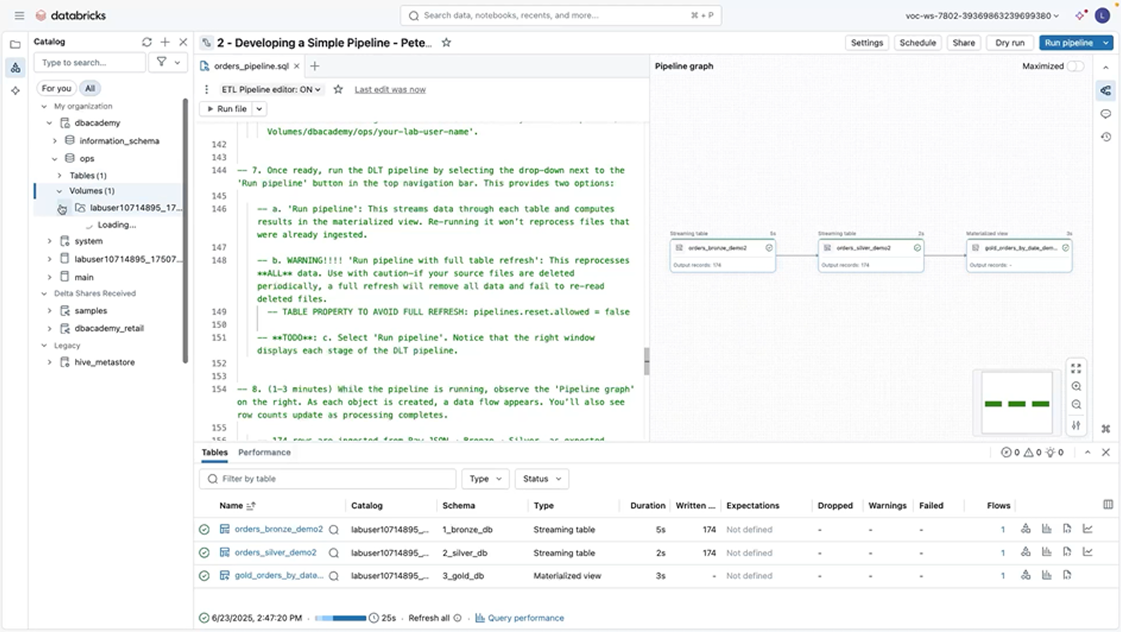
Built-in data quality checks like the schema coherency and how the violating rows should be treated (such as dropping the failed rows or stopping the ingestion process) help identify issues early in the pipeline, reducing the propagation of errors downstream. This approach improves trust in analytics and AI outputs while reducing the operational burden associated with manual validation and remediation. With the built-in notification systems, the responsible members can be notified about the status of each job through emails, Teams, or other messaging systems.
The result is a set of curated, governed data products that can be reused across analytics and AI use cases. This is supported through Databricks features like Unity Catalog, which allows teams to define ownership, access controls, and data lineage for each dataset. Teams can assign responsible users or stewards for a data product, maintain metadata and documentation, and enforce policies for security, quality, and compliance, ensuring that curated data products remain reliable and well-governed.
C. Analytics and Business IntelligenceAnalytics workloads operate directly on the same data foundation. Databricks provides SQL-based analytics capabilities that integrate with existing BI tools, allowing organizations to continue using familiar reporting environments. By eliminating the need to duplicate data into separate analytical systems, organizations can accelerate insight generation while maintaining a single source of truth. This consistency is particularly important for financial reporting, risk analysis, and management dashboards.
Governance and security are foundational requirements for enterprise data platforms and when not fully fulfilled could increase cyber risk, operational risk, and/or reputation risk beyond the company’s risk capacity. Databricks embeds governance across data, analytics, and AI workloads rather than treating it as an afterthought.
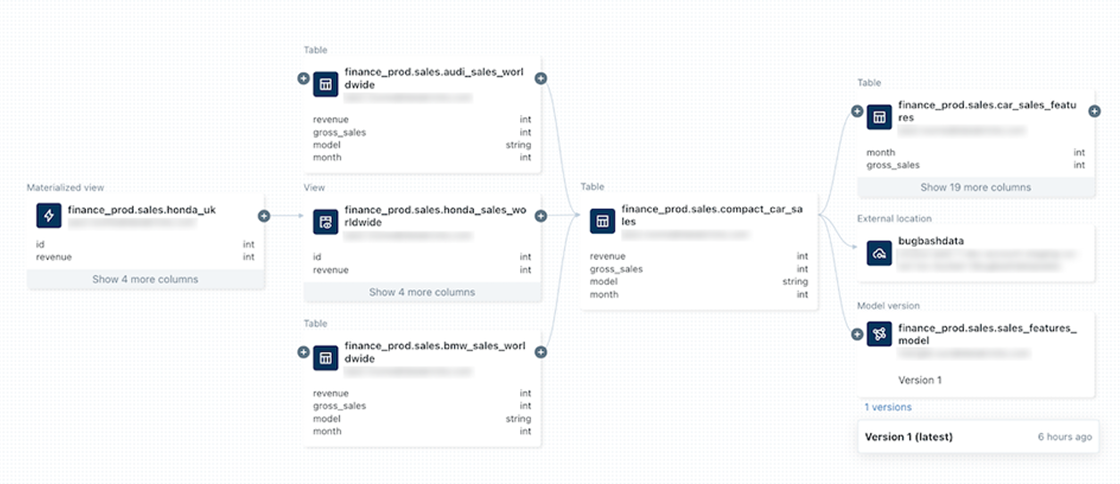
Unified governance enables centralized management of access controls, metadata, and usage policies. Fine-grained controls allow organizations to restrict access at the level of individual volumes, files, tables, columns, or rows, aligning with internal policies and regulatory requirements. End-to-end lineage and auditability provide transparency into how data is created, transformed, and consumed. This capability is critical for regulated industries, where organizations must demonstrate control over data usage and decision-making processes. By integrating governance directly into the platform, Databricks reduces friction between innovation and control. Figure 3 shows an example of Unity Catalog’s data lineage feature inside Databricks, where one can click on a dataset or table and view a visual graph showing all upstream sources, transformations, and downstream consumers.
Incremental Adaptation of Databricks
Upscaling analytics and AI capabilities always comes with its risks, regulatory compliances, and/or complex architecture. By combining open technologies, centralized governance, and support for both structured and unstructured data, the platform promises to allow organizations to modernize their data landscape incrementally. Faster access to insights, a more reliable foundation for advanced analytics and AI, and improved transparency across the data lifecycle would be achievable without requiring a disruptive replacement of existing systems.
A typical example could be new sets of data being delivered by current resources and business teams considering the application of these new sets, either for introducing new procedures or enhancing the current ones. In classical structures, these teams have to contact DevOps or IT teams to make the changes in the current ETL pipeline and inform the affected business units to test the new outcomes. This process could last from a couple of weeks to months depending on the agility of the teams involved and means missed opportunities for the institute in general.
Data Intelligence Platform, as shown in Figure 1, helps to overcome this issue, business units can directly look into the newest versions of the incoming data. With Databricks, users can explore datasets by using notebooks, SQL Analytics, or dashboards to filter, sample, and query data without waiting for the traditional ETL pipeline. This enables teams to quickly test hypotheses, validate new data, and iterate on processes, accelerating insights while allowing IT and DevOps to focus on other priorities. Users can even leverage Databricks’ AI capabilities early in the exploration phase, analyzing a variety of raw inputs (CSV, JSON, TXT, etc.) without needing to create tables or modify existing data layers.
Conclusion: Building a Future-Ready Data Platform
As data, analytics, and AI continue to converge, organizations need platforms that balance flexibility with control. Fragmented architectures struggle to meet these demands, particularly in regulated environments.
Databricks provides a unified foundation for managing data, analytics, and AI on a scale. Combined with the right strategy and execution approach, it enables organizations to modernize their data landscape while maintaining trust, security, and compliance.
UCG helps organizations turn this foundation into real, measurable business values supporting a data platform that is not only modern, but future-ready.
