
Management Summary
Background: Our customer, a large German bank, manages a data warehouse that supplies business-critical data to the its departments. At the end of each business day, current data snapshots from internal and external banking systems are ingested, normalised to create a unified source of truth, and made available for data consumers.
Challenge: The legacy data processing framework has grown organically over the last 30+ years and is now reaching its limits. End-to-end processing runtimes need to be reduced: Upstream delays from internal and external providers are cascading into downstream delays, leading to increasing Service Level Agreement (SLA) breaches with data consumers are increasing. Pipeline re-runs are costly and bind operational capacity.
Project: Since migrating to a new platform was not economically viable, UCG was tasked with analysing the existing data processing pipelines, identifying ‘in-situ’ improvements, and creating and executing an implementation plan while ensuring uninterrupted service for downstream data consumers.
Result: We improved total processing time by an average of 36% (corresponds to ~6h saved), significantly surpassing our customer’s expectations. Select data processing jobs experienced runtime improvements of over 90%. The data warehouse modernisation was successful: The performance improvements created buffers that protect against external disruptions and safguard SLA compliance.
Banks Rely on Business-Critical Legacy Systems
Compared to other industries, banks face extraordinary regulatory scrutiny, including their IT systems and processes. One consequence is that, once a legacy IT system has been established, it becomes uneconomical to replace.
This is the situation our customer, one of the 10 largest German banks, found itself in. The bank’s central data warehouse revolves around IBM’s relational database solution, Informix SQL. Informix used to be a prominent OLTP datastore (trailing only behind Oracle and Microsoft) in the 1990s and had wide adoption in the financial services sector. While still being maintained today (unlike, e.g. Sybase SQL Anywhere after acquisition by SAP), IBM’s main focus now lies on Db2 as its Cloud- and ‘AI-ready’ database solution.
The Challenge: Modernisation to Improve Reliability, SLA Adherence, Operability
In order to provide this unified view of the bank’s data, many GB of data from 30+ systems must be ingested and flow through the three layers at the end of each business day.
The goal: Modernise the data processing pipelines in the data warehouse in order to…
- Improve SLA compliance with internal consumers, e.g. data underlying various risk reports must be provided to the risk management teams by 8am so that a daily risk report can be delivered to the board by noon.
- Ensure timely regulatory reporting to BaFin and ECB/Bundesbank, either through the regulatory reporting teams or directly via APIs.
- Improve reliability in the face of upstream delays from internal and external data providers.
- Improve operability such that the data warehouse team can perform timely re-runs in case of job failures.
- And ultimately to reduce costs by minimising the time spent operating the data processing pipelines.
The challenge: Figuratively speaking, the data warehouse can be thought of as the bank’s heart, pumping fresh data to the bank’s departments. Because implanting a new “heart” was not feasible, UCG was tasked with upgrading the existing system: analysing all components of the legacy data processing framework, identifying inefficencies, and creating a comprehensive plan for modernising the identified components.
Technology Stack: Informix SQL Warehouse & Java Batch Processing
Our client uses a custom batch processing framework written in Java that interacts with the Informix database through the Informix JDBC drivers. The processing is highly sequential and is orchestrated by the workload automation platform Automic (formerly UC4).
Our solution: leaving no stone unturned
We put all components of the data procesing framework under the microscope to identify opportunities for improvement. We identified a core design pattern of the architecture as critical for optimisation:
- Query: SQL statements are run against the database, returning a result set.
- Reading of the input records: The framework reads from the result set row by row, resulting in a list of input record objects.
- Transformation: Each input record is transformed into an output record object.
- Writing of the output records: The output records are written into the database.
For individual jobs with a runtime of 30+ minutes, we studied the underlying SQL statements. Mirroring the complex environment, these statements are often complex joins of several tables from the normalisation layer, typically 100+ lines long.
SQL query optimisation is a classic topic with many angles of attack, and we won’t go into details here (we refer to the Informix Query Performance presentation by Mike Walker).
The art of query optimisation is to optimise just enough: We are optimising given the current state of the environment today (e.g. the state of other tables in a join). If optimiser directives are too restrictive, the query engine will not be able to react to future changes in the environment.
An example: This particular job processes all active loans (several hundred thousand rows), joins customer data (several million rows), does comparisons with yesterday’s snapshot of the table, and computes regulatory metrics based on the loan amounts. In this case, it turns out the bottleneck was one join in a series of several joins. For some reason, the engine was not able to effectively scan the particular table. Forcing the engine to hold the table in memory improved query execution time from 15 minutes to appr. 3 minutes Further optimisations resulted in a final execution time of 45 seconds.
2. Multi-Threaded Reading
After a ResultSet is retrieved, the data is read from the Informix SQL database in a row-by-row manner. Reading happens in a Java thread in the background such that comparisons between the current and the previous records are possible. However, the orchestration of the different threads left room for improvement.
We replaced the existing implementation with a much more efficient threading model, significantly improving the time needed to retrieve rows from the result set. As a side effect, this new implementation also resulted in simpler, more readable code. Early tests showed a speed-up of appr. 10-20% on average.
3. Improving JDBC write performance
In the last component in the batch framework, the transformed records are written to a target table in the Informix SQL database. Our customer’s implementation uses batches of PreparedStatements that are executed in parallel through manual orchestration of Java threads. This implementation was already quite performant and well-tuned to the specific setup.
Still, there was room for improvement. In particular, we found that the Informix JDBC driver’s preparedStatement.executeBatch() has undocumented commit behaviour: by default, the driver commits after every record, and not, as the method name suggests, after every batch of records. We can only speculate that this a regression that was likely introduced in a previous update of the Informix JDBC driver. Adjusting the commit behaviour lead to an immediate improvement of another roughly 20% in processing runtime.
Extensive testing
Changes to the Java batch framework affect almost all data processing jobs in the data warehouse. Unlike operating on an open heart, software changes can and must be tested, and this testing must be proportional to the introduced risk. In this specific case, the testing was extensive: components were first tested individually, mocking other components where necessary, and with synthetic data, development data and production data. Then, all components were integrated and again retested with different types of data. Lastly, a complete job plan was executed using production data.
Technical Result: ~36% Processing Time Saved
During testing it became apparent that the integration of these changes would yield significant synergy effects: the increased throughput when reading from the database now fully saturates the writing operations, which were accelerated independently.
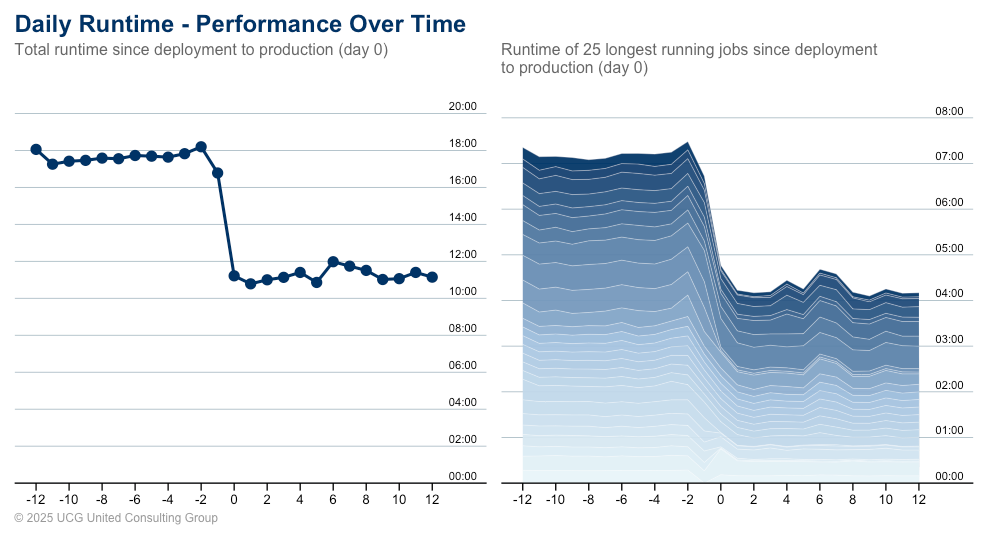
All in all, the total processing time (the sum of processing times of all individual jobs, ignoring the fact that many jobs run in parallel) was reduced by appr. 6 hours from 18 hours to 12 hours. This corresponds to a speed-up of roughly 36 % (all changes were measured 10 days before and after deployment to production).
Some processing jobs saw improvements of 90+%. In the graph one can clearly spot the drop in total processing time when the changes were deployed to production.
Business Impact: Better Reliability and Improved SLA Adherence
The increase in data throughput directly led to increased reliability and better operability of the data processing pipelines. SLA adherence improved significantly, and data can now be delivered more timely to internal as well as external consumers, in particular regulators such as BaFin, the Bundesbank, and the ECB. The system is more resilient to delays from source providers. Operating the data processing pipelines requries less resources and is less costly.
In a nutshell, we modernised the data processing pipelines and extended the useful life of the legacy system. This bought our customer valuable time to work on implementing a new, modern solution in the future.
What our customer had to say
Here is what our customers had to say:
Feedback from the technical lead of the data warehouse:
“Your performance improvements to the Java framework will be remembered. They had a significant impact and helped us move forward. Thank you very much!”
From the data warehouse product owner:
“Re-runs are now significantly faster. Whereas in the past they often finished only after 5pm, I’m now confident to say we will be done by 1pm.”
From the head of the department:
“You gave our data management system another lease of life. SLA-compliance has improved significantly. Thank you for that!”
Leanings
As external consultants, we are uniquely positioned to bring a new perspective to established legacy systems. Even, or maybe even especially, in organically grown code bases, it is possible to achieve substantial performance gains. There is no “silver bullet” - all components of a complex system have to be analysed in detail, line by line, to unearth opportunities for modernisation. Rapid prototyping is essential to test whether performance improvements do in fact materialise.
